Streamlining document management processes is crucial for enhancing efficiency and productivity in today's digital age. Leveraging advanced technologies like Optical Character Recognition (OCR) and Natural Language Processing (NLP) can significantly automate and enhance the processing of large volumes of text data, especially in industries dealing with extensive document workflows.
We have developed a cutting-edge system that harnesses the power of OCR, NLP, and deep learning techniques to streamline the processing and analysis of PDF documents. Our system offers comprehensive features for document classification, information extraction, and logical separation.
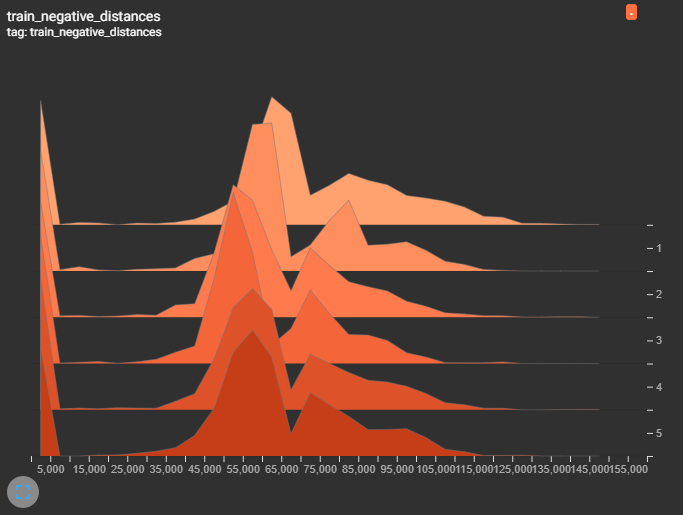
Our system employs a trained Mask R-CNN model to detect document elements such as headers, footers, and signatures, regardless of format, layout, font, or language. Information extraction is then facilitated through OCR and NLP techniques, capturing vital details such as object type, year, service provider, manufacturer, company name, and content type. The process ensures robust document classification and identification.
We trained
2
different computer-vision models for sorting and understanding of technical documents
Sorted and annotated
698
Documents in BIM360Docs
Each trained on more than
10 000
Technical-document pages, including drawings
To guarantee accurate document organization, our system intelligently determines whether consecutive pages belong to the same document using OCR, NLP, and computer vision techniques. This logical separation ensures precision in sorting and categorizing documents, enhancing overall efficiency in document management.
Our solution seamlessly integrates with BIM 360 Docs, a cloud-based document management software, allowing easy transfer of organized documents. Implementation involves a C# application calling a Python API for PDF document processing. Advanced techniques, such as document feature detection, OCR preprocessing, and NLP with OpenAI's GPT-3.5-turbo, are employed for information extraction. Document separation utilizes a computer-vision siamese network architecture, logistic regression, and NLP for precise and enhanced results. This holistic approach ensures a seamless and advanced document processing experience.
Experience unparalleled productivity as our solution evolves into a comprehensive document sorting application, capable of autonomously processing and organizing PDFs. Transform your data into a searchable knowledge database, empowering your organization with actionable insights. Our advanced solution promises seamless automation, unmatched accuracy, and unparalleled productivity.
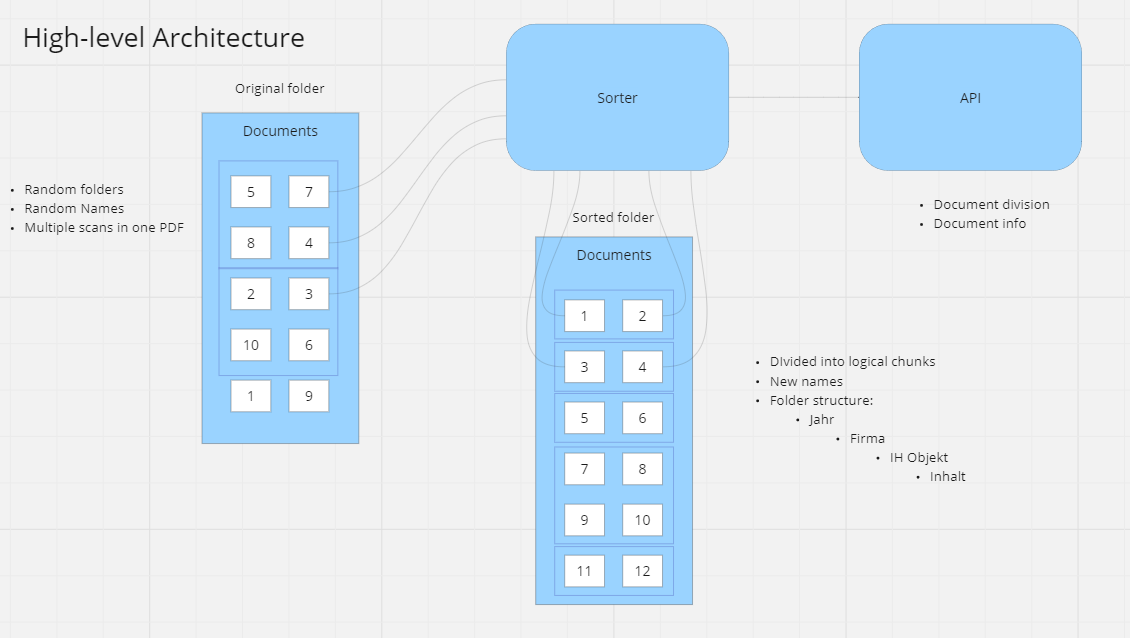
Original folder
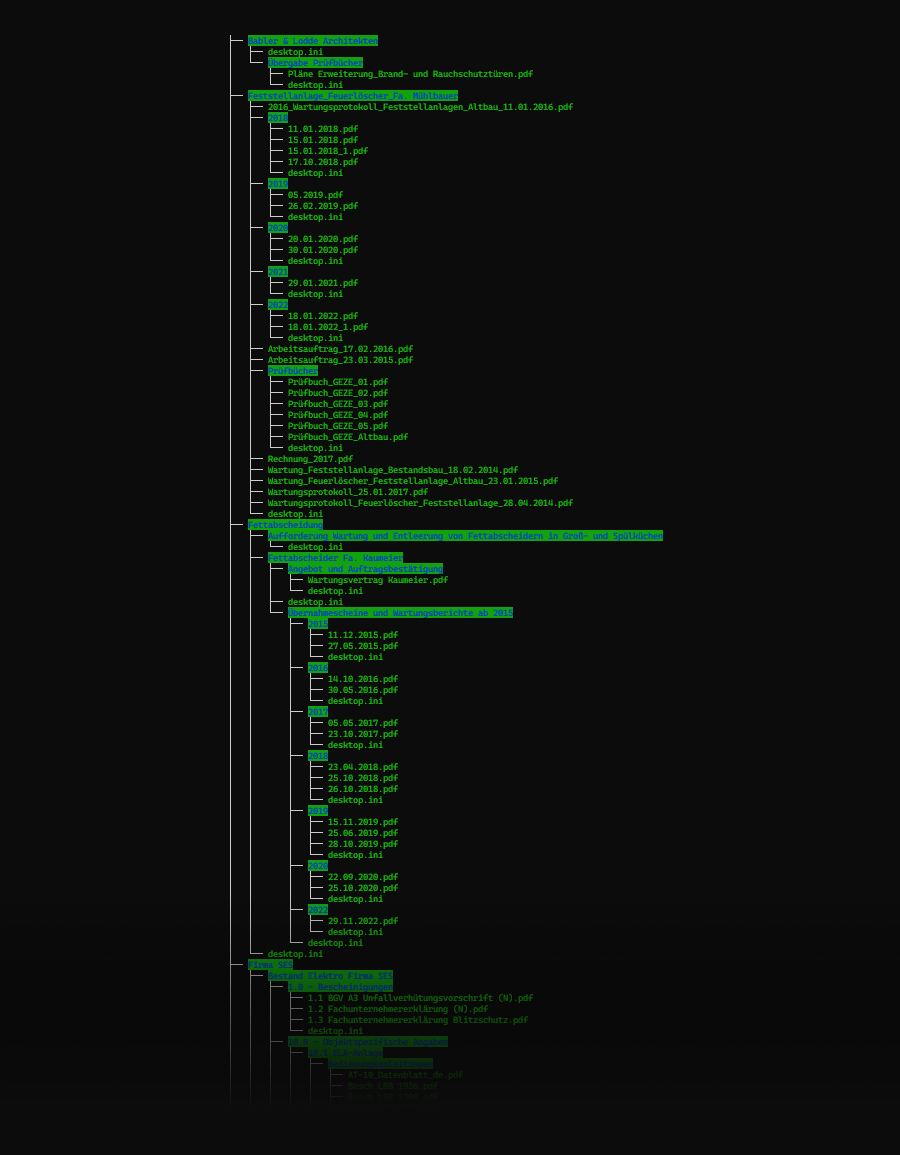
Sorted folders in BIM360
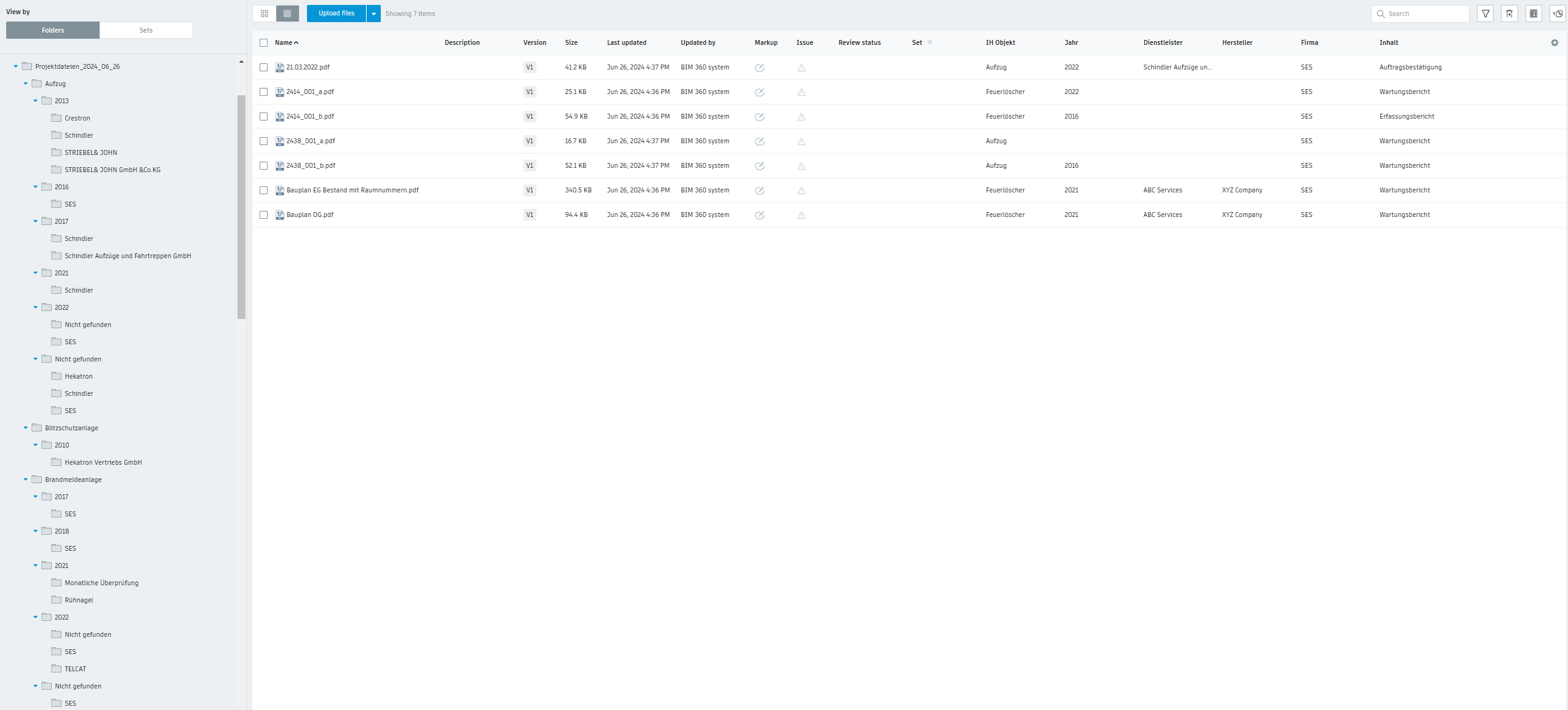
Gallery
Client
ioLabs AG (own R&D project)
Partner
-
Credits
ioLabs AG
|
Technology
Pytorch Lightning
MaskRCNN
Langchain
OpenAI API
LLM embeddings
GPT-3.5-Turbo
ResNET
Siamese networks
FastAPI
Logstash and Kibana
BIM 360 Docs
|