Die Optimierung von Dokumentenverwaltungsprozessen ist entscheidend, um die Effizienz und Produktivität im digitalen Zeitalter von heute zu steigern. Die Nutzung fortschrittlicher Technologien wie Optical Character Recognition (OCR) und Natural Language Processing (NLP) kann die Verarbeitung grosser Textdatenmengen erheblich automatisieren und verbessern, insbesondere in Branchen, die mit umfangreichen Dokumentenworkflows umgehen.
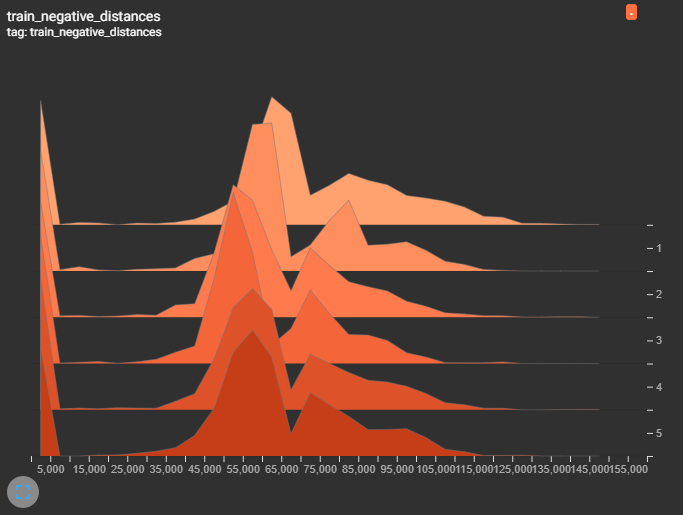
Wir haben ein hochmodernes System entwickelt, das die Leistung von OCR, NLP und Deep-Learning-Techniken nutzt, um die Verarbeitung und Analyse von PDF-Dokumenten zu optimieren. Unser System bietet umfassende Funktionen für die Dokumentenklassifizierung, Informationsextraktion und logische Trennung.
Unser System verwendet ein geschultes Mask R-CNN-Modell, um Dokumentenelemente wie Kopfzeilen, Fusszeilen und Signaturen zu erkennen, unabhängig von Format, Layout, Schrift oder Sprache. Die Informationsextraktion wird dann durch OCR- und NLP-Techniken erleichtert, die wichtige Details wie Objekttyp, Jahr, Dienstleister, Hersteller, Unternehmensname und Inhaltstyp erfassen. Der Prozess gewährleistet eine robuste Dokumentenklassifizierung und Identifikation.
Wir haben
2
unterschiedliche Computer-Vision-Modelle für das Sortieren und Verstehen von technischen Dokumenten geschult.
Sortiert und annotiert
698
Dokumente in BIM360Docs
Jedes wurde auf mehr als
10 000
Seiten technischer Dokumente, einschliesslich Zeichnungen, geschult.
Um eine genaue Dokumentenorganisation zu garantieren, bestimmt unser System intelligent, ob aufeinander folgende Seiten zu demselben Dokument gehören, indem es OCR-, NLP- und Computer-Vision-Techniken verwendet. Diese logische Trennung gewährleistet Präzision beim Sortieren und Kategorisieren von Dokumenten und steigert die Gesamteffizienz in der Dokumentenverwaltung.
Unsere Lösung integriert sich nahtlos in BIM 360 Docs, eine cloudbasierte Dokumentenverwaltungssoftware, und ermöglicht einen einfachen Transfer von organisierten Dokumenten. Die Implementierung umfasst eine C#-Anwendung, die eine Python-API für die Verarbeitung von PDF-Dokumenten aufruft. Fortgeschrittene Techniken wie die Erkennung von Dokumentmerkmalen, OCR- Vorverarbeitung und NLP mit OpenAI's GPT-3.5-turbo werden für die Informationsgewinnung eingesetzt. Die Dokumententrennung verwendet die Architektur des Siamesischen Neuronalen Netzes für die Computer Vision, logistische Regression und NLP für präzise und verbesserte Ergebnisse. Dieser ganzheitliche Ansatz gewährleistet eine nahtlose und fortschrittliche Dokumentenverarbeitungserfahrung.
Erleben Sie beispiellose Produktivität, während unsere Lösung zu einer umfassenden Anwendung für die Dokumentsortierung wird, die in der Lage ist, PDFs autonom zu verarbeiten und zu organisieren. Verwandeln Sie Ihre Daten in eine durchsuchbare Wissensdatenbank und befähigen Sie Ihre Organisation mit handlungsfähigen Erkenntnissen. Unsere fortschrittliche Lösung verspricht nahtlose Automatisierung, unübertroffene Genauigkeit und beispiellose Produktivität.
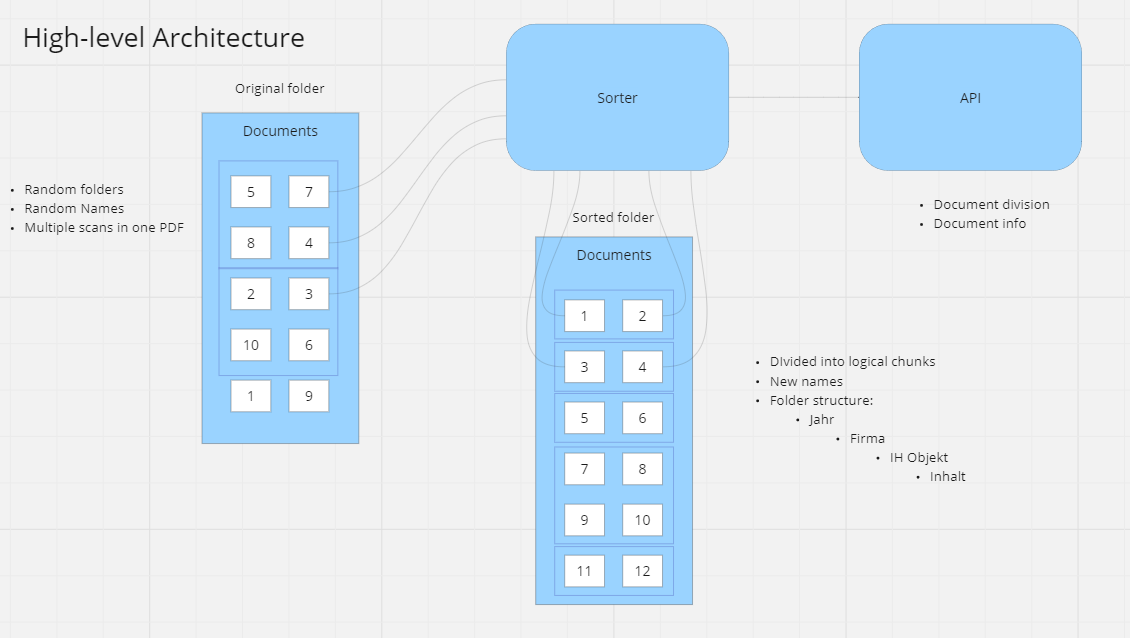
Originalordner
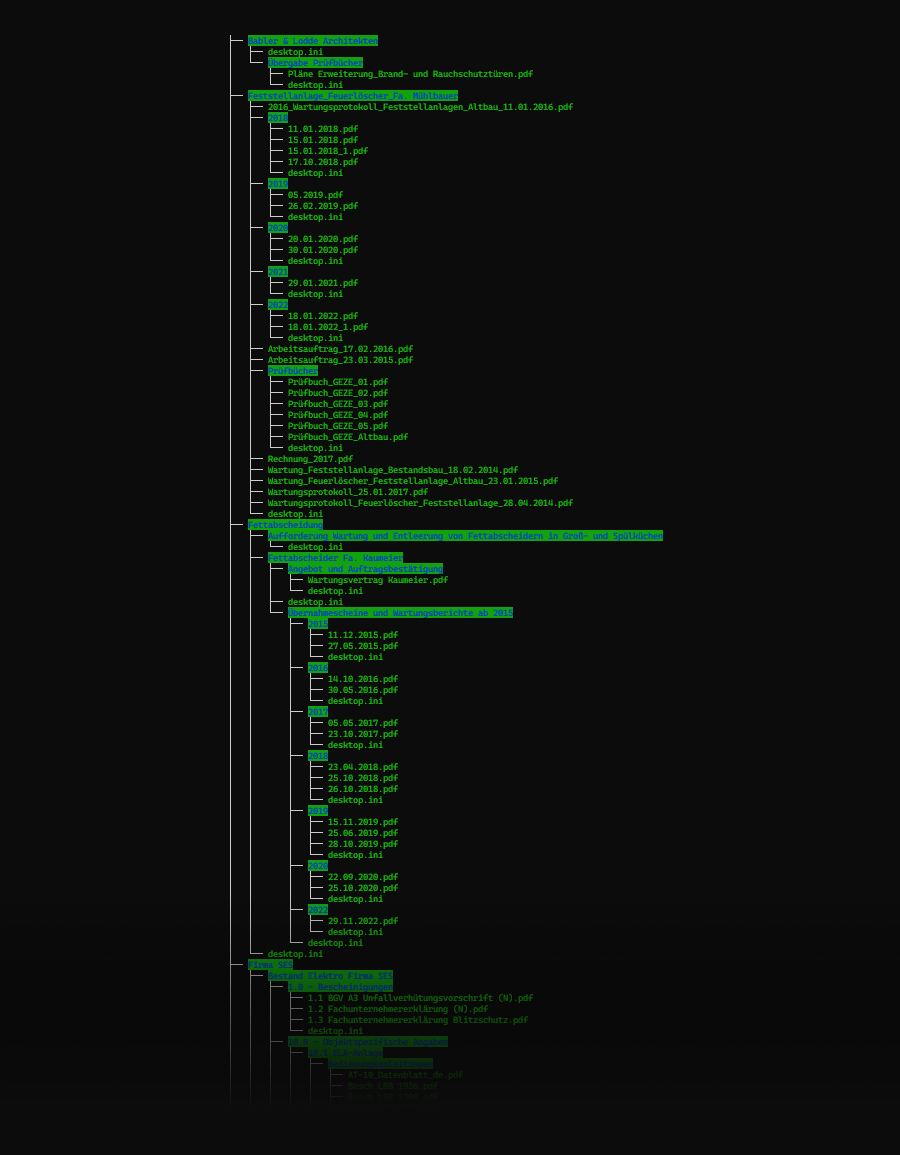
Sortierte Ordner in BIM360
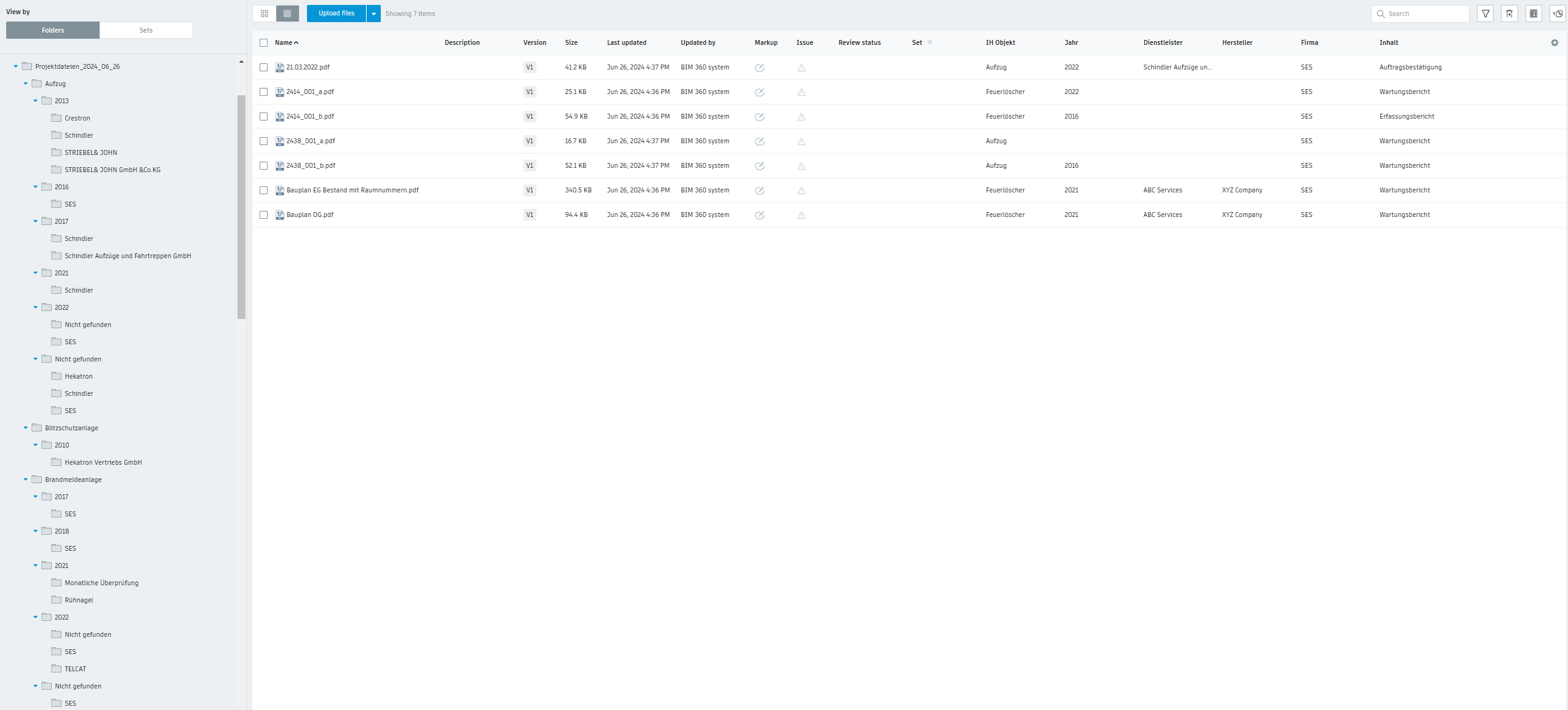
Galerie
Kunde
ioLabs AG (own R&D project)
Partner
-
Credits
ioLabs AG
|
Technologie
Pytorch Lightning
MaskRCNN
Langchain
OpenAI API
LLM embeddings
GPT-3.5-Turbo
ResNET
Siamese networks
FastAPI
Logstash and Kibana
BIM 360 Docs
|